

Photo by cottonbro studio on Pexels
When The New York Times sued OpenAI and Microsoft in December 2023, it didn't just file a complaint. It built a fortress.
The document spans 69 pages of densely packed allegations, but its true weight lies in what's attached to it: thousands of citations to registered works, a meticulously catalogued trademark portfolio, and page after page of side-by-side comparisons showing ChatGPT reproducing Times content verbatim, with the copied text highlighted in red.
This was not the work of lawyers alone. It was the product of a sophisticated, multi-disciplinary investigation, one that other plaintiffs in the AI copyright wars would do well to study.
The Three Layers of Proof
The NYT complaint rests on three distinct categories of evidence, each addressing a different aspect of the infringement claim.
1. The Copyright Layer: Thousands of Registered Works
The complaint doesn't just allege that The Times owns copyrighted material; it proves it. The plaintiff lists over 3 million registered copyrighted works and attaches multiple exhibits cataloguing specific articles, series, and investigations.
Exhibits A through I and K establish a clear chain of ownership that no defendant can plausibly dispute. This matters because copyright infringement requires proof of ownership, and the NYT team made sure that element was ironclad from Day One.
2. The Trademark Layer: Protecting the Brand
The complaint also asserts claims for trademark dilution, citing federally registered marks including "The New York Times," "nytimes," and "nytimes.com". These are central to the allegation that Defendants' products generate "hallucinations," false information falsely attributed to The Times, that tarnish the brand's reputation for accuracy.
Example 1: Bing Chat fabricated an entire paragraph about Steve Forbes's daughter and attributed it to a Times article that never mentioned her.
Example 2: It invented a list of "heart-healthy foods" that The Times never published.
These aren't just technical errors; they're brand injuries documented in detail.
3. The Output Layer: The Smoking Gun

Source: CourtListener, Case No. 1:23-cv-11195
The most visceral evidence is in Exhibit J, a 69-page compendium of side-by-side comparisons.
In page after page, the NYT team shows prompts they entered into ChatGPT and the resulting output, with copied text highlighted in red. One example shows ChatGPT reproducing the first several paragraphs of the Pulitzer Prize-winning "Snow Fall" series verbatim, content that sits behind a paywall.
The effect is devastating. In some examples, the copied sections stretch for multiple pages, proving that the model had memorized the works, not just learned from them. This is not "fair use"; this is substitution. A user who receives the first five paragraphs of a paywalled article from ChatGPT has no reason to visit The Times's website.
The Dataset Evidence That Ties It Together
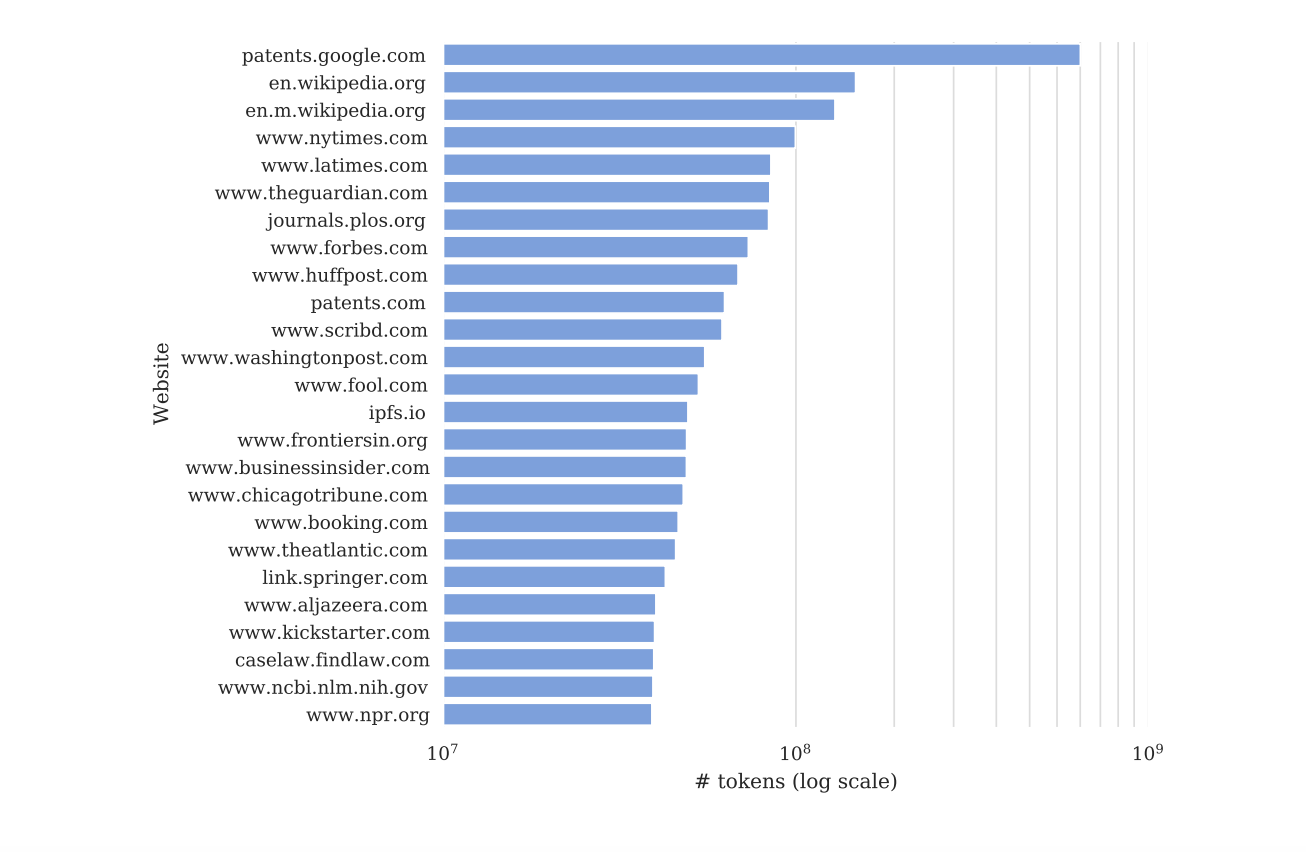
Source: CourtListener, Case No. 1:23-cv-11195
All of this output evidence would be meaningless without proof that the works were actually used in training. That's where the dataset analysis comes in.
Datasets like Common Crawl are large-scale collections of web content that are routinely used to train large language models (LLMs). Common Crawl works by periodically crawling the public web, much like a search engine indexes pages. It visits publicly accessible sites, copies the text it finds, and packages it into datasets that AI companies and researchers download for training. NYT content entered Common Crawl because nytimes.com was publicly accessible on the web; when the crawler visited those pages, it captured the content. The complaint reveals that in a filtered 2019 snapshot of Common Crawl, the domain nytimes.com is the most highly represented proprietary source, and the third overall behind only Wikipedia and a U.S. patent database. It accounts for over 100 million tokens. This was the digital equivalent of a multi-decade archive fed into a machine that would later compete with its creators.
The Broader Context: A Crisis of Consent
The NYT's evidence lands at a moment of profound shift in how the internet relates to AI. According to a study published in July 2024 by the Data Provenance Initiative, the web is rapidly closing itself off.
A robots.txt file is a text file placed in the root of a website that instructs crawlers which pages they may or may not access. Site owners use it to tell bots, "Do not crawl this path" or "Do not index this content." It is a convention, not legally binding, but many crawlers honor it. Research shows that many high-quality data sources are now restricting access via robots.txt or terms of service changes because they do not want their data used to build commercial systems that threaten their livelihoods. The study found that 25 percent of data from the highest-quality sources has been restricted; in one dataset alone, as much as 45 percent of the data is now restricted. For many creators, the use of their data is not acceptable even if the AI paraphrases, because it still utilizes their proprietary labor without permission or compensation.
"We're seeing a rapid decline in consent to use data across the web that will have ramifications not just for AI companies, but for researchers, academics and noncommercial entities," said Shayne Longpre, the study's lead author.
What This Means for Litigators
For lawyers preparing AI copyright cases, the lesson is clear: the evidence is in the datasets, and it's in the outputs. Common Crawl is publicly available, and its indices can be searched to quantify domain presence. Quantifying this presence requires specialized technical analysis of these massive datasets, the kind of work that bridges the gap between raw data and admissible evidence.
The NYT team showed the necessary steps:
- Establish ownership with registered copyrights and trademarks.
- Identify the datasets used (Common Crawl, WebText, The Pile) and quantify presence.
- Document outputs that prove memorization using side-by-side comparisons with red highlighting.
As the industry sees blowback from creators whose livelihoods are threatened, the NYT lawsuit has provided the definitive template for the legal battles ahead.
Sources: CourtListener, Case No. 1:23-cv-11195. NYT article cited: AI Data Restrictions
Disclaimer: I used AI to help draft and refine this post, but the ideas, analysis, and editorial judgment are my own.
About the Author
Salma Saad is the founder of Rule26 AI and a CIPP/US certified technical expert. With 20+ years in software engineering, she provides technical memos that translate complex AI systems into actionable evidence for litigation teams.